



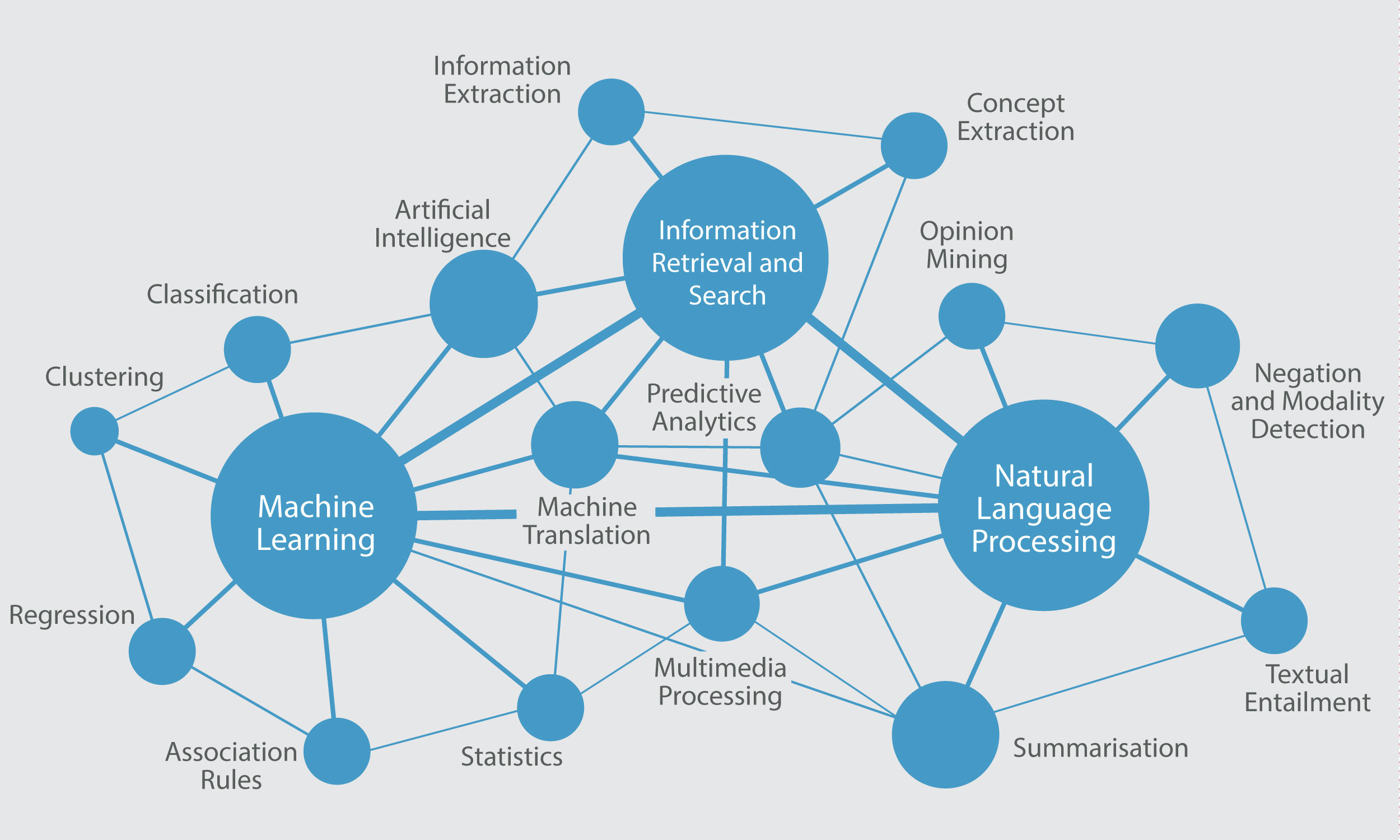
The Text and Data Mining field covers different research areas and the methods they encompass can be applied in different contexts and for several purposes, depending on the needs of the specific task and the availability of data and expertise. To this aim, rather than being an exhaustive list of techniques and research directions, in Deliverable 3.11 Figure 4 Micro view on TDM environment, tries to depict the scale and potential scientific interaction, as well as the broad knowledge required for creating a successful scientifically sound TDM application. In particular, three main scientific areas can be identified, that is,
- Machine learning which studies the automated recognition of patterns in data, and develops algorithms able to learn tasks without explicit (human) instruction or programming. Learning is based on data exploration and is aimed at generalizing knowledge and patterns beyond the examples that are fed to the algorithm at training stage
- Information retrieval and search which focuses on the optimisation of search methods that index vast amounts of content and allow the location and extraction of the most relevant facts for any question and user type can vary from simple retrieval of all the items (e.g. full documents) within a collection that contain user-requested words in metadata fields or structured databases, to more sophisticated search and ranking of the results based on the presence of combinations of important words and numbers in different sections of texts or data fields (Baeza-Yates and Ribeiro-Neto, 1999). It is important to note that, although TDM is using information retrieval algorithms as one of the components within the TDM framework, it goes beyond the simple retrieval of whole documents or their parts. Within the IR framework, the task of knowledge processing and of new knowledge creation still resides with the user, while in case of full TDM the extraction of novel, never-before encountered information is the main goal of the TDM technology implementation (Hearst, 1999).
- Natural language processing which aims at developing computational models for the understanding and generation of natural language. NLP models capture the structure of language through patterns that map linguistic form to information and knowledge or vice versa; these patterns are either inspired by linguistic theory or automatically discovered from data. The NLP community is subdivided into groups that focus more on the spoken or written content, i.e. speech technologies (ST) and computational linguistics (CL). ST researchers work with audio signals, synthesising and recognising speech and paralinguistic phenomena. Once speech content is transcribed in a textual representation, it can be further treated as text for TDM. CL researchers target syntactic and discourse structures; their algorithms help to understand the basic concepts, relations, facts, and events expressed in textual content.
A part from them, other relevant research directions for TDM applications are:
Statistics, as a field of mathematics in general and machine learning in particular, provides its practitioners with a wide variety of tools for data collection, analysis, interpretation or explanation, and presentation.
Visualisation of intermediate results and output of the ML, IR, and NLP algorithms is an intrinsic part of all the TDM constituent technologies. Visualisation proves to be very helpful for researchers in different fields such as bioinformatics, when for example the mining of proteins behaviour described in a set of publications is visualised in one scheme; or in text mining, when a word cloud, with words in different size and colours depending on their frequencies, gives a general impression on the most frequent terms of the collection of documents.
Classification/Categorization/Clustering of content within a collection, in order to split (in a supervised or unsupervised manner) these into groups of certain types based on content, represent a TDM preprocessing step on the collection level, as these categories are used for further specific mining of the collections content. Machine learning (ML) algorithms represent a dominant solution for this task, e.g. the Naïve Bayes approach (Lewis, 1998), decision rules (Cohen, 1995), and support vector machines (Joachims, 1998). While classification algorithms identify whether an object belongs to a certain group, regression algorithms estimate or predict a response as a value from a continuous set.
Association rule-learning algorithms allow for the discovery of interesting relations between variables within large databases (Agrawal et al., 1993). For example, when one mines a large database of customer shopping behaviour, association rules help to define what types of products or services are usually being sold together. This information can help to adjust and tailor marketing campaigns, as well as make product arrangements in the stores more efficient.
Information extraction (IE) is a wide concept that covers the inference of information from textual data. Examples of types of extracted information are statistics on the usage of terms, the occurrence of named entities in text and their relations or associations according to certain classification schemes, and the presence of specific facts or logical inferences expressed in texts (e.g. interactions between genes, logical proofs, or the inference of logical consequences and entailment expressed in the text).
Term or Concept extraction is a first step for further IE, as one needs to define the terms of importance for the corpus to start its processing. Once these terms, being specific for the topic to conceptualize a given knowledge domain, are extracted, an ontology of the field can be created for further IE task implementations.
Negation and modality (or hedge) detection is an important aspect of TDM, as negation and hedging constructions in the text (such as “Our results cast doubt on finding X of Author Z” or “We found that finding Z does not apply to context Y”) offer crucial evaluations of reported facts.
Sentiment analysis, or opinion mining, aims to determine the attitude of a speaker or a writer with respect to some topic or the overall contextual polarity of a document. The attitude may be his or her judgment or evaluation, the affective state of the author, or the intended emotion the author intends to convey to the reader.
Summarisation of a given text or a set of texts is the task of creating a shorter text that captures the most crucial information from the original texts. First, the crucial content to be summarised is defined, and then, depending on the task, it is condensed into a new representation that may consist of sentences or parts from the original documents (extractive summarisation), or that is a newly created text or multimedia document that rephrases the summarised message (abstractive summarisation).
Predictive analytics term covers the methods that analyse previous usage or transactions statistics and, based on these results and trends, offers predictions on further systems development.
Machine translation targets human quality level of translation of written or spoken content from one language to another via usage of computers. Although it originally started as rule-based systems taking into account a lot of linguistic knowledge, nowadays the pioneers in the field use Big Data size collections and deep learning algorithms to train their systems and to achieve performance improvements.
Multimedia processing allows further mining of all aspects of multimedia content, varying from the audio stream of a given video to visual concepts extraction and annotation, person and object discovery and localisation on the screen. This direction of research and applications gain a lot of importance for TDM, due to the fact that contemporary Internet users share and create a lot of multimedia contents that, for example, reflect their opinions and spread information about events.
1 Deliverable 3.1 Research Report on TDM Landscape in Europe
 data analytics pays off 10:1. Or, does it?")




