




Big Data has been a buzz word for a number of years now. It is all around us - from Amazon analysing our purchases to make recommendations to us, supermarkets doing the same to entice us with discounts, all types of companies analysing the web, or scientists looking at journal articles to find hitherto unknown benefits relating to use of a drug. The possibilities are as endless as our imaginations.
This new form of research, based on computers analysing vast “lakes” of data, is something that governments and the European Commission[1] have sought to support. The health benefits of better understanding how the human body works speak for themselves, as do the potential increases in GDP that come from companies selling more products, or making better management decisions based on analysis of all the data at their disposal. These technologies also feed into the recent hype around Artificial Intelligence (AI).
The Horizon 2020 funded project Future TDM[2] has just spent the last 2 years looking at how we can further remove barriers and encourage the greater take up of data analytics technologies in Europe. In 2016 it was estimated that the value of Big Data in Europe was $9.4 billion, with TDM accounting for $2.5 billion of that. The project also estimates that the value of the European economy will grow by an extra 1.9% by 2020 thanks to big and open data.
With such economically important matters at play, Future TDM was funded by the European Commission in 2015 to look at what can be done to create further value for the economy. With such a wide ranging project it isn’t possible to even remotely do it justice in such a short blog, but just some of the main themes and some of the key findings are as follows:
Technology and Infrastructure
Interestingly one thing that many respondents highlighted was the lack of Big Data in the public domain. This means that data scientists are often not so experienced at working on “Big Data” when they start in the workplace. Wikipedia, licensed under CC BY SA, and semi-structured as a data set was often quoted as the largest single source of freely available data.
The infrastructure and technology is also very fragmented. As the need to store and analyse data increases, so do the challenges posed by interoperability across different data models, architectures and formats. Researchers and companies are increasingly wanting to combine differing data sets into new architectures, systems and products, which would be facilitated by far higher levels of interoperability than exist at the moment.
Other findings included the vast difference between European languages in terms of the resources and tools (text analysis, speech analysis, machine translation etc) available for people to use. Inevitably with English generally having good availability across the board, whereas for example speech analysis was poor for Romanian, Croatian, Latvian and Lithuanian and machine translation tools having weak or no support for many languages including Swedish, Portuguese, Danish, Finnish etc. This disparity also showed itself in the languages that data analytics and Big Data is written about with English being, perhaps not unsurprisingly far and away the main language used in academic articles on the topic.

Economic
Commercial activity around TDM is also picking up in Europe. Not unexpectedly however, this tends to be concentrated in the bigger EU countries (UK, Germany, France, Spain, Italy) and is mainly geared towards vertical applications and various types of analytics services. As outlined above it is estimated that the European economy will be responsible for a nearly 2% increase in European GDP by 2020.
As Big Data is becoming a mainstream process, the number of businesses who are struggling with the first stage of Big Data development, (i.e. the building of an infrastructure), is rapidly diminishing. As these challenges become less pronounced, another challenge becomes more urgent, namely that of skills acquisition. Without people with the requisite skills, such as statisticians and data scientists, Big Data will remain in a raw and unusable form.
Although data analysis is becoming more widespread, the shortage of talent is preventing companies from translating analytical insights into business actions. Even business giants have recognised that they have failed to exploit the full potential of their data due to a shortage of internal capabilities and their access to skilled analysts. It also isn’t just the “hard skills” that data scientists and programmers have that are required, companies also need people with the vision and business acumen to make the most out of the data opportunities that are out there. Companies need to address the transformation of organisational culture to make it more “data savvy”. This will enable them to implement the work-products of data miners and analysts throughout their business to drive innovation and / or efficiency savings.
Education
The lack of skills that businesses are identifying in part is because universities are not producing enough people with either the hard data science skills, or equally importantly, people aware of the benefits that data analytics can bring to an organisation.
What was very evident from Future TDM’s research was the lack of strategic thinking at senior management levels in universities to promote this relatively new type of research. In the main, outside of the field of computer science, we found students and staff are relying on their own personal networks in order to do (or have done for them) mining of text and data. Very few universities indeed are approaching this strategically.
Of the few examples we were able to find, Ghent University was the most advanced in their thinking although this focussed generally around the issue of data management rather than data analytics per se. In 2015 prompted by the library, the university carried out a survey and series of interviews across all research and education faculty members to understand what skills the university should focus on investing in and supporting. Among other things, the results of this project highlighted a need for better skills in data management and data science.
The university library used the results of this project as evidence to investigate how education in data management skills could be introduced into core university curricula. Teaching of some of these skills has already been implemented in doctoral schools, and ultimately the library’s project aims to make these part of the curricula of every Master’s degree by 2018 (with the depth and detail covered varying by field). Although not explicitly educating students about TDM itself, laying the foundations for good data management practices is a key first step towards supporting greater use of data analytics.
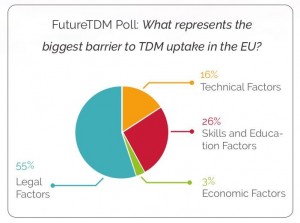
Legal
A small poll on data analytics undertaken by the Future TDM project shows that people believe legal issues to be the biggest barrier to the further uptake of data analytics technologies in Europe.
The legal barriers divide into copyright, database right and data protection law issues. In terms of copyright and database rights despite the very wide spread adoption of data analytics globally, and the clear economic benefits of Big Data and AI, European legislators have been slow to act. Currently in Europe according to our research only the UK[3], France and Estonia have exceptions for text and data mining. In the UK, like in all other EU member states, even this exception is limited by the Information Society Directive (also known as the Copyright Directive) to non-commercial mining only. The French exception[4] appears even more limited, allowing only non-commercial research of in-copyright works for the purposes of “public research” only.
In terms of copyright law, rightsholders have an “exclusive right” to control the acts of” reproduction” (i.e. making a copy), and “communication to the public.” (i.e sharing / dissemination to others.) In terms of database law rightsholders have an exclusive right over the extraction and re-utilisation of substantive materials held within a database.
Given that data mining usually requires the making of a copy, and the extraction of “knowledge” from the information within which the data sits, this means that exceptions are required in law to facilitate data mining or the “exclusive rights” remain in place. If an exception does not exist, permission from the rightsholders will be required. Given the main organisations, and arguably the largest benefit from TDM, will come from the private sector the project has concluded that commercial and non-commercial organisations and individuals should be able to mine information to which it has lawful access. In order to allow any such exception to not be undermined, the project also advocates that this should not be undermined by contracts, or the use of technical protection measures.
Despite the massive economic benefits of TDM being driven by the private sector, the current discussions in Brussels on an updated Copyright Acquis ( the Digital Single Market Directive) are focussing only on allowing research institutions (which may or may not include libraries) from being able to data mine in copyright works. For example this would mean that small European start-ups mining the open web, through to pharmaceutical companies like Bayer doing the same activity could not do this without a licence from each and every rightsholder. Something that is clearly impossible. The only light on the horizon on this front, is coming from the European Member States (European Council) who are currently debating the merits of a non-mandatory exception that would allow commercial companies to data mine materials they have lawful access to, including the open web.
Looking at data protection law, how Big Data marries with the General Data Protection Regulation also presents a number of interesting challenges but will often depend exactly on the details of the activities being undertaken. If we take web mining as one lens for looking at data protection law and Big Data, the internet will often include personal data put on the web by the individual themselves, but also placed there by third parties in the form of opinions or in the course of news reporting. Some of the issues of compliance with data protection principles include, transparency, limitation on purpose (only using the data for the purpose it was collected), data minimisation and accuracy.
Data analytics can be undertaken in a dynamic environment where what you are analysing changes rapidly, as your thoughts on a particular topic may change. It will be difficult in such cases to be transparent as to exactly for what purpose data mining is being undertaken. In order to create a lawful basis for using personal data, where the data is received direct from the data subject (e.g. a person’s own website) the General Data Protection Regulation Art.13 requires that the person or organisation using the data informs the person of a number of different sets of information. Analysing large numbers of websites at scale to establish whose website the data has been obtained clearly makes this impossible, and yet no such exemption is provided for in the GDPR.
Data protection law requires that data collected for one purpose is not used for any non-compatible purposes, although there are exemptions for this if undertaking scientific, historical or statistical research. How to think about this as a company web mining hundreds of thousands of web pages, created for numerous different purposes unknown to the company, is perhaps another example where European law does not reflect the realities of mining the internet. Another set of obligations on organisations using personal data is to ensure that no more data than is required is used, and that it is kept accurate and up to date. The point of Big Data is that the data employed is rich and varied, and in the case of web mining the use of personal data may or may not be pertinent to the analytics being undertaken. Being forced to minimise personal data feels in certain instances where the focus is not particularly oriented to individuals to be antithetical to Big Data itself. As an “independent” bystander analysing material from the open web, an organisation is similarly not in a position to make a judgement as to whether the data is accurate or up-to-date. Applying data protection principles to web mining, throws up a myriad of issues sometimes creating the impression that the law is trying to place a square peg in a round hole.
This article in no way does justice to the large amount of work the Future TDM project undertook over a period of 2 years. In the final assessment meeting in Brussels the reviewer stated that the work we had undertaken was arguably the single biggest study ever taken on data analytics. Certainly we met many interesting people at the forefront of technical innovation, and discovered many interesting things along the way. If you are at all interested in any of the issues raised by this article I would encourage you to explore the project website further https://www.futuretdm.eu/
Please also find practitioner guidelines on legal, licensing, data management and the TDM issues faced by universities here (5.3) : https://www.futuretdm.eu/knowledge-library/
[1] https://ec.europa.eu/digital-single-market/en/big-data
[2] Future TDM project partners were the Foundation Project Poland, Ligue des Bibliothèques Européennes des Recherches, Ubiquity Press, Athena Research and Innovation Centre, Open Knowledge Foundation, SYNYO gmbh, University of Amsterdam, British Library and Radboud University.
[3] https://www.legislation.gov.uk/ukpga/1988/48/section/29A
[4] Loi N° 2016-1321 du 7 Octobre 2016 pour une République numérique. Art.38.





