




We, as FutureTDM, we were happy to organise and moderate a panel discussion at the Annual Meeting 2016 of the Association for Information Science and Technology (ASIS&T) in Copenhagen on October 17, 2016. The panel aimed to discuss the legal, economic and practical impact and merits of an exception for text and data mining (TDM) under copyright law. This is the first blog post in a small series, which reflects and follows on from the panel discussion. In this post, I will outline what was the motive and input for this discussion. Following blog posts in this series will comprise contributions by the panellists, but anyone is invited and encouraged to provide her or his view on this platform.
In the panel discussion, two ‘designs’ of a TDM exception, as well as the impact of a TDM exception in general, were the topic for debate. The first one concerned the TDM exception as proposed by the Commission in its recent proposal for a directive on copyright in the Digital Single Market. It permits the making of reproductions of copyrighted works to carry out TDM by research organisation with lawful access, as long as it is done for scientific research purposes. This exception may benefit a certain group of users, but it is questionable whether it is able to adhere to the fundamental principles of copyright law. We therefore introduced to adopt an alternative, more fundamental, approach for designing a TDM exception. It incorporates an idea, of which we are currently considering and examining its impact and desirability within the FutureTDM project.
As a fundamental principle of copyright law, ideas and facts are not protected. Only the expression conveying the ideas and facts is protected – this is commonly referred to as the idea-expression dichotomy. Pursuant to this doctrine, human reading and re-use of facts and ideas gained from such reading (and other ways of extracting information from works by the human senses), cannot be prevented by the copyright owner. This principle is currently under threat, as TDM activities potentially fall within the scope of copyright law.
TDM can be seen as ‘reading’ by a machine: it reads the works, analyses them according to an algorithm set by the TDM user, and subsequently passes any patterns, facts or other insights on to that user. However, unlike human reading, this ‘machine reading’ cannot be carried out without any creation of reproductions. First, lawfully acquired or accessed work might be transformed into a workable – possibly annotated – dataset for the machine. Second, reproductions are necessarily made within the computer hardware, and in particular in random-access memory (RAM). Since these reproductions fall within the ambit of the broadly defined reproduction right, such ‘reading’ is subject to the exclusive control of the right holder(s); current exceptions under (European) copyright law do not sufficiently cover such reproductions or at least do not provide the legal certainty to TDM users. Therefore, new ways of discovering knowledge – that can only be extracted from large amounts of works, which is impossible for humans to deal with – are restricted. Hence, facts and ideas that can only be found using these technologies are restricted due to copyright law.
 The Commision’s proposal does not guaran
The Commision’s proposal does not guaran
tee this full use of potential new knowledge. By
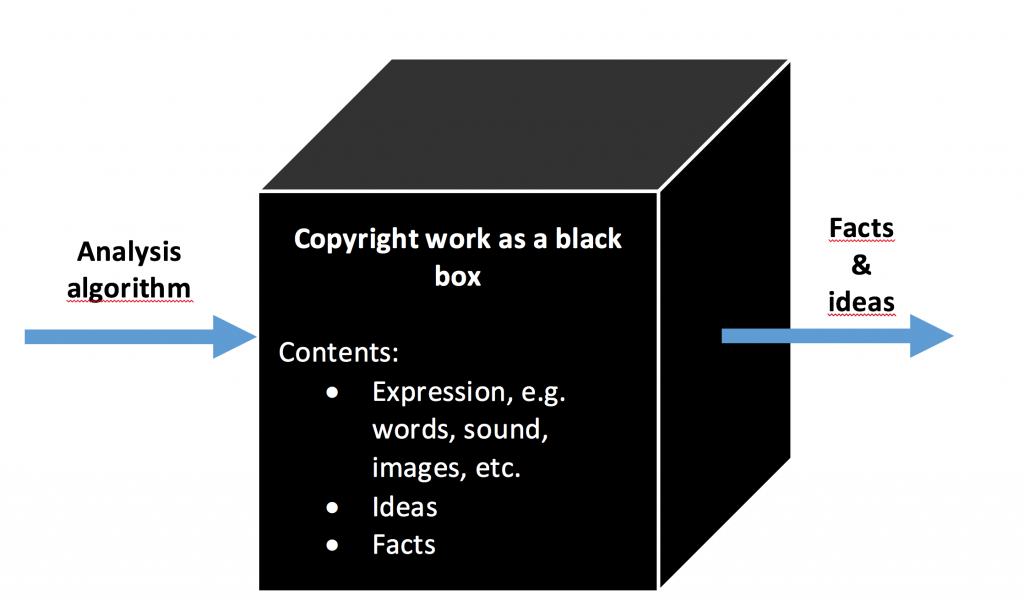
contrast, An idea that originates from Lucie Guibault, which is to regard copyright works as black boxes, may do. For a human, a copyright work is not a black box because he or her reads, watches, listens or otherwise consumes the expression of a work. If the expression is poorly written or otherwise constructed, a natural person might choose not to consume it. For a human, a good research paper is not only good research paper because of the message it conveys; without a proper expression, the paper loses its value. This is different in the case of TDM, where the miner is only interested in the knowledge underlying the work. In fact, without the human ever taking notice of the expression, the machine reads the work and extracts the facts and ideas therefrom. So, in the context of text and data mining, a work is nothing more than a black box: it provides input, e.g. in the form of an algorithm, and receives a certain output from the work.
This analogy does not come out of thin air. What is more, this concept is already present in the European copyright framework, namely in the Software Directive (2009/24/EC). Article 5(3) of the directive explicitly permits to carry out black box analysis on a copyrighted computer program, subject to a few criteria. Similarly, we can design such an exception for copyright works in general, adapting these criteria to apply in those cases as well, as can be seen in below table.

This was the idea that was discussed at the panel with invited experts from the fields of law, economy and TDM research:
- Dr Matěj Myška, senior assistant professor at Masaryk University, on the legal feasibility impact and shortcomings of the discussed TDM exceptions
- Dr Christian Handke, assistant professor at Erasmus University, on the economic impact and advantages of a TDM exception
- Penny Labropoulou, senior researcher at Research Centre Athena, on the practical feasibility and desirability of TDM exception
We look forward to see their contributions, and we welcome other contributions as well! Please contact me at M.Caspers@uva.nl if you would like to contribute to this blog post series.
// All blog posts are the personal opinion of the bloggers. For more information see FutureTDM's DISCLAIMER on how we handle the blog. //




